Doblaje multi-voz local: vídeos con varios hablantes sin depender siempre de cloud.
Dublar un vídeo con una sola voz ya requiere cuidado. Dublar varios hablantes es otra liga: hay que reconocer quién habla, asignar voces, revisar traducción, cuidar timing, crear subtítulos y exportar un resultado que no suene a automatización barata.
VANIV apunta a un workflow local-first para creadores que quieren traducir, doblar y revisar vídeos con varios hablantes con más control sobre voces, archivos, subtítulos y exportación.

Multi-Voice-Dubbing no es solo “poner otra voz”
El doblaje multi-voz necesita mantener quién habla, cuándo habla y qué tono tiene cada persona. Si todos los hablantes suenan igual, el espectador pierde contexto. Si las voces se mezclan mal, el vídeo parece roto.
En entrevistas, cursos, podcasts, debates, tutoriales con invitados o demos con varios roles, una sola voz puede destruir la dinámica. El resultado quizá se entiende, pero no se siente natural.
Por eso el objetivo no es solo traducir palabras. El objetivo es reconstruir una experiencia: voces diferenciables, texto natural, timing razonable, subtítulos útiles y audio final limpio.
Por qué el doblaje básico falla con varios hablantes
Un sistema simple puede funcionar para un narrador único. Pero con varios hablantes aparecen problemas: cambios rápidos, interrupciones, frases cortas, risas, silencios, nombres propios y tonos distintos.
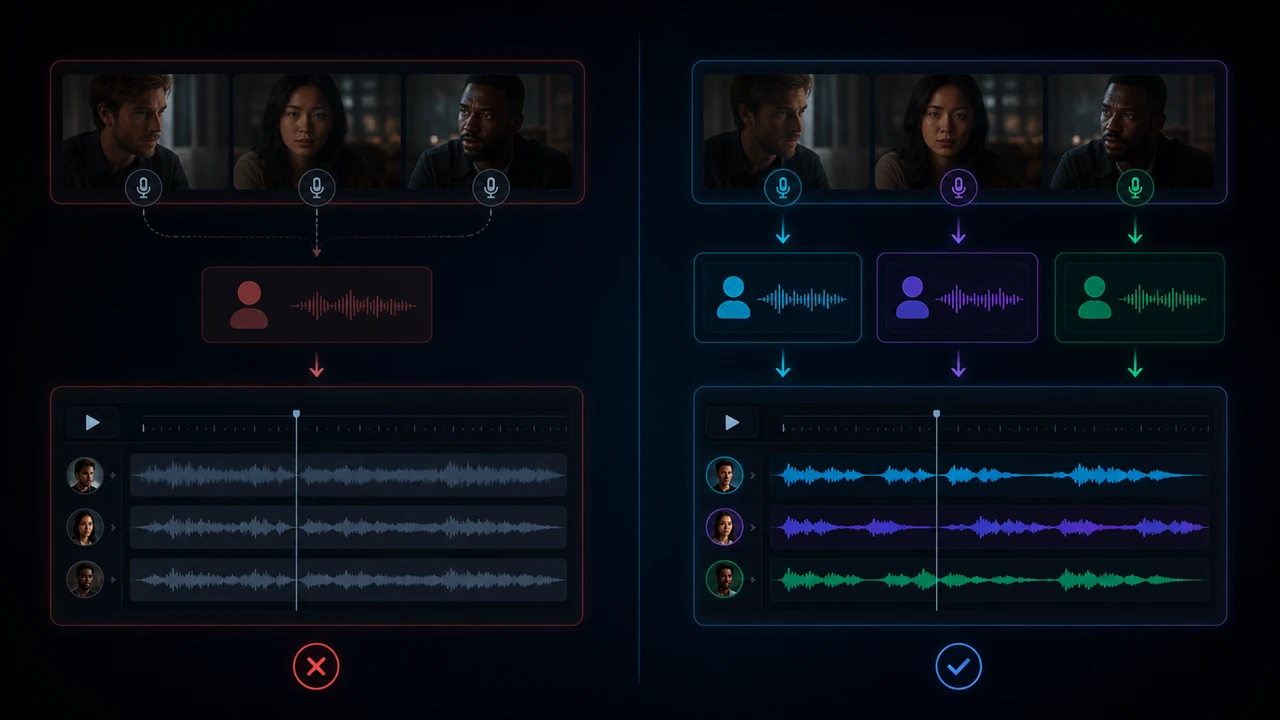
Todos suenan igual
Se pierde quién habla y el vídeo parece menos humano.
Timing roto
Una traducción más larga puede entrar tarde o pisar al siguiente hablante.
Subtítulos confusos
Sin estructura, el espectador no sabe quién dice qué.
Qué necesita un buen workflow local multi-voz
| Elemento | Por qué importa | Error típico |
|---|---|---|
| Transcripción | Base para traducción, subtítulos y timing. | No revisar nombres, cortes o frases difíciles. |
| Speaker mapping | Define quién habla en cada segmento. | Mezclar hablantes o asignar voces incorrectas. |
| Voces | Deben diferenciar roles sin imitar personas sin permiso. | Usar una voz genérica para todos. |
| Traducción | Debe sonar natural y caber en el tiempo. | Traducir literal y romper ritmo. |
| Subtítulos | Ayudan a comprensión y revisión. | Generarlos tarde o sin revisar. |
| Export | El resultado final debe verse y escucharse completo. | Confiar solo en una demo corta. |
Cuándo basta una sola voz y cuándo necesitas multi-voz
No todos los vídeos necesitan varias voces. Si tienes un narrador único, una sola voz puede funcionar perfectamente. Multi-voz se vuelve importante cuando el contenido depende de diálogo, roles o contraste entre personas.
| Tipo de vídeo | Single-Voice puede bastar | Multi-Voice ayuda mucho |
|---|---|---|
| Tutorial con un narrador | Sí. | No siempre necesario. |
| Entrevista | Rara vez. | Sí, porque hay varios hablantes. |
| Podcast con invitados | Puede confundir. | Sí, por roles y ritmo conversacional. |
| Curso con diálogos | Depende. | Sí, si hay personajes o ejemplos hablados. |
| Demo de producto | Sí, si solo narra una persona. | Sí, si hay soporte, cliente o vendedor. |
Dónde el doblaje multi-voz local aporta más valor
Entrevistas y canales con invitados
El espectador entiende mejor quién habla y por qué cambia el tono.
Lecciones con ejemplos dialogados
Varios roles hacen más natural una explicación.
Clips traducidos
Conservar roles evita que el diálogo parezca narración plana.
Material de clientes
El control local ayuda cuando hay archivos sensibles y varias voces.
Demos con cliente y soporte
Voces distintas hacen más claro el flujo de conversación.
Versiones internacionales
Más idiomas requieren más control sobre voces, texto y timing.
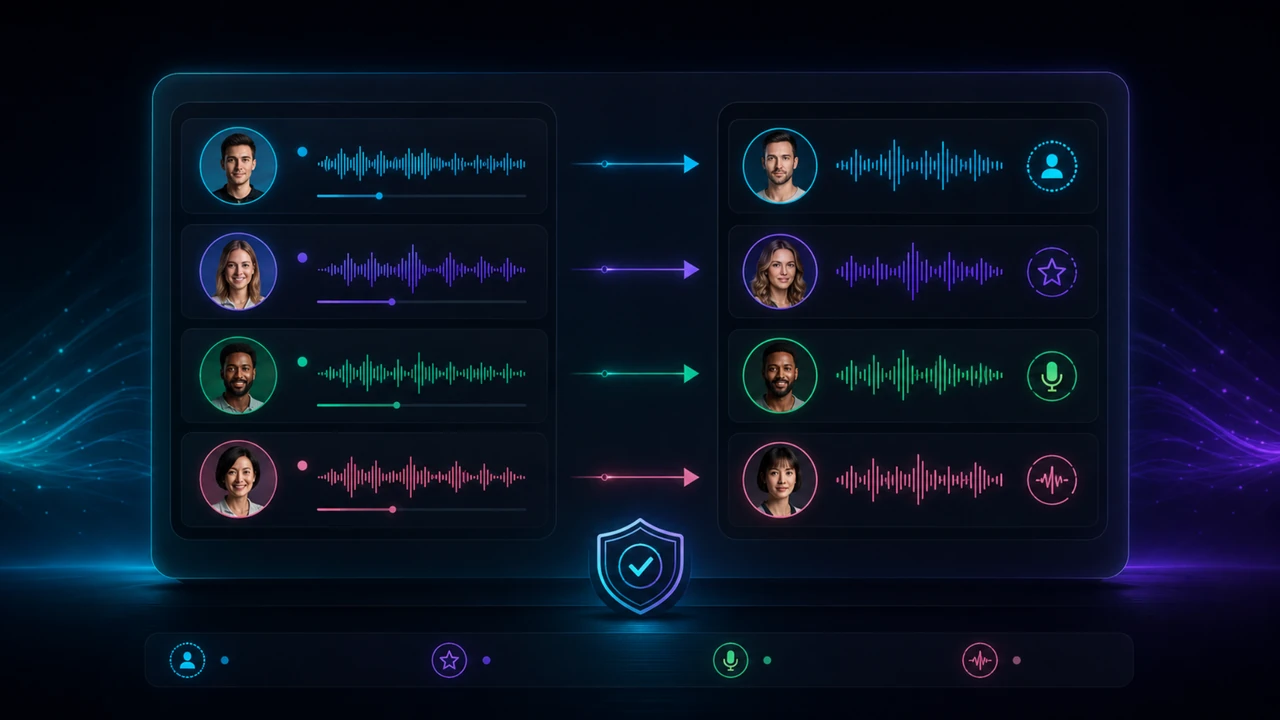
Speaker mapping: calidad y responsabilidad en el mismo punto
Asignar voces no es un detalle técnico. Es una decisión editorial. Una voz equivocada puede cambiar cómo se percibe una persona, una frase o una intención.
Si usas voces clonadas, deben ser propias o autorizadas. Si usas voces diseñadas, deben diferenciar roles sin fingir que son personas reales. El objetivo es claridad, no engaño.
En proyectos serios conviene revisar el speaker mapping manualmente. La automatización puede ayudar, pero no debería tener la última palabra en un vídeo que vas a publicar o entregar a un cliente.
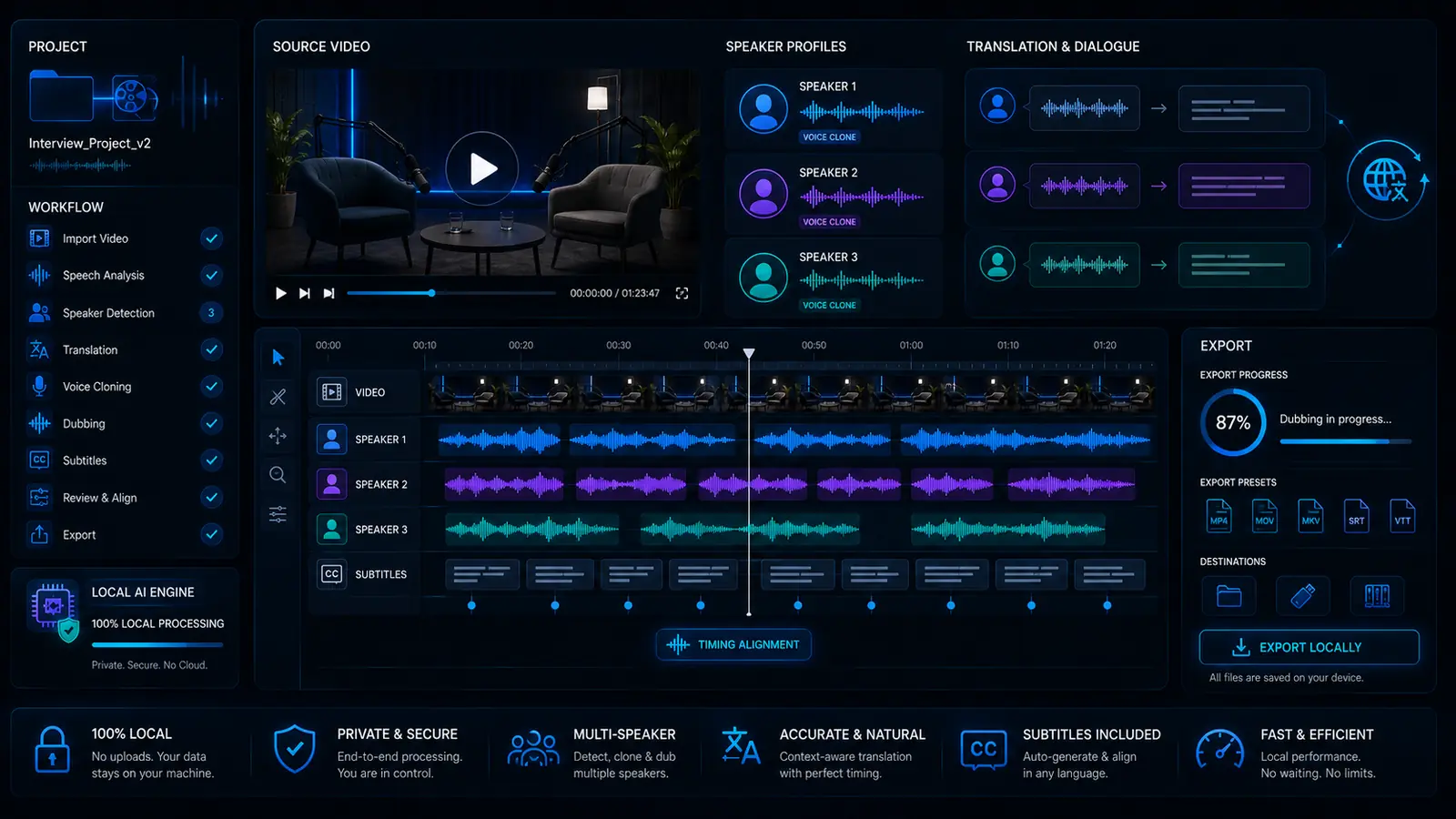
Cómo VANIV Studio encaja en el workflow multi-voz
VANIV tiene más sentido cuando no ves el doblaje como un botón mágico, sino como un flujo: importar vídeo, analizar audio, revisar hablantes, traducir, asignar voces, generar pistas, revisar subtítulos y exportar.
La meta no es prometer perfección automática. La meta es organizar el proceso de forma local-first para que puedas repetirlo con más control.
Timing: el enemigo silencioso del doblaje multi-voz
Una traducción puede ser correcta y aun así no caber en el vídeo. En multi-voz esto duele más, porque un hablante puede pisar al siguiente o romper una pausa importante.
El timing no se arregla solo con una voz bonita. A veces hay que simplificar frases, dividir segmentos, ajustar subtítulos o aceptar que una traducción literal no sirve para doblaje.
La pregunta final no es “¿está traducido?”. La pregunta final es: “¿se puede ver completo sin que el audio moleste?”
Subtítulos: control de calidad y red de seguridad
En multi-voz, los subtítulos ayudan a revisar texto, hablantes y timing. También hacen el vídeo más accesible y más fácil de consumir en redes.
Si la voz entra tarde, el subtítulo lo delata. Si el hablante cambia mal, el subtítulo ayuda a encontrar el error. Por eso los subtítulos no son decoración: son parte del control de calidad.

Hardware para doblaje multi-voz local
Multi-voz suele exigir más que TTS simple. Hay vídeo, audio, transcripción, voces, subtítulos, exportación y varias iteraciones. GPU, RAM y SSD influyen mucho en comodidad.
Una GPU NVIDIA RTX moderna ayuda. 12 GB VRAM pueden ser una entrada mínima para ciertos workflows, pero no es una zona cómoda para todo. 32 a 64 GB de RAM y SSD NVMe rápido hacen el flujo más estable.
Más hardware no arregla mala traducción ni voces sin permiso. Pero sí reduce fricción cuando necesitas repetir pruebas.
Qué preparar antes de tu primer test multi-voz
- Usa un vídeo propio o autorizado.
- Empieza con 60 a 120 segundos, no con un vídeo largo.
- Comprueba que el audio original sea entendible.
- Identifica cuántos hablantes reales hay.
- Decide si usarás voces diseñadas o voces autorizadas.
- Revisa transcripción y nombres propios.
- Comprueba subtítulos y timing antes del export final.
- Mira el vídeo completo antes de publicar.
Lo que el doblaje multi-voz local no soluciona automáticamente
Local no convierte un vídeo malo en una producción premium. Si el audio fuente es confuso, si varios hablantes se pisan o si la traducción es literal, el resultado seguirá necesitando revisión.
Tampoco resuelve permisos de voz. Clonar o imitar una voz sin autorización es un problema de confianza, no un problema técnico. Y no hay interfaz bonita que convierta eso en buena idea.
La promesa honesta es otra: un workflow local puede darte más control para revisar, corregir y repetir. No elimina el criterio humano.
Errores frecuentes en multi-voice dubbing
Empezar con vídeo largo
Primero valida un clip corto. Lo contrario es deporte extremo con GPU.
No revisar hablantes
Un speaker mapping incorrecto rompe toda la experiencia.
Traducir literal
La frase debe caber en tiempo y sonar natural.
Usar voces sin permiso
Solo voces propias, autorizadas o diseñadas sin imitar personas reales.
Ignorar subtítulos
Son control de calidad, no adorno.
No revisar export
Una demo buena no garantiza un vídeo final bueno.
E-E-A-T: cómo evaluar si el resultado es publicable
Mira el vídeo entero. No solo escuches el primer segmento bueno. Evalúa si cada hablante se entiende, si las voces son diferenciables, si el timing funciona y si los subtítulos ayudan.
Después pruébalo en móvil. Muchas personas verán el vídeo ahí. Si en móvil no se entiende quién habla o la mezcla suena mal, todavía no está listo.
Para clientes o marca, guarda notas: fuente del vídeo, permisos de voz, idioma, voces usadas, fecha, versión y observaciones de calidad. Eso parece aburrido, pero evita caos cuando el proyecto crece.
Por qué multi-voz necesita más revisión que single-voice
Single-Voice-Dubbing puede perdonar más errores. Si solo hay un narrador, el espectador sigue el hilo aunque la voz no sea perfecta. En multi-voz, cada error se nota más rápido porque afecta a quién habla, cuándo habla y cómo se interpreta la escena.
Cuando dos o tres personas conversan, el doblaje tiene que conservar estructura. Una respuesta debe sonar como respuesta. Una interrupción debe entrar en el momento correcto. Un cambio de hablante debe reconocerse sin que el espectador tenga que adivinar.
Por eso multi-voz no debería tratarse como “TTS repetido varias veces”. Es una tarea de producción: texto, voces, segmentos, subtítulos, mezcla y exportación tienen que trabajar juntos.
La revisión de hablantes es el seguro contra resultados raros
La automatización puede ayudarte a detectar hablantes, pero no deberías confiar a ciegas. En vídeos reales hay ruido, risas, solapamientos, frases cortas y cambios de tono. Todo eso puede confundir la asignación.
Un speaker mapping incorrecto no es un error pequeño. Si una frase sensible, una opinión o una broma se asigna a la persona equivocada, el contenido cambia de significado. En proyectos de clientes, eso puede ser bastante más que “un bug simpático”.
La regla práctica: revisa los primeros minutos con atención. Si el sistema falla ahí, no escales a un vídeo largo sin corregir el proceso.
Cómo evaluar voces para varios hablantes
Las voces deben diferenciarse lo suficiente para que el espectador entienda el diálogo. Pero tampoco deben convertirse en caricaturas. Una entrevista seria no necesita voces teatrales; necesita claridad y coherencia.
| Criterio | Buena señal | Mala señal |
|---|---|---|
| Diferenciación | Se reconoce quién habla sin mirar subtítulos. | Todas las voces suenan iguales. |
| Naturalidad | La voz encaja con el contexto del vídeo. | Suena exagerada o fuera de tono. |
| Ritmo | La voz cabe en el segmento sin correr. | Habla demasiado rápido para encajar. |
| Claridad | Se entiende bien en móvil y auriculares. | Las palabras se mezclan o cansan. |
| Responsabilidad | Voz propia, autorizada o diseñada sin imitar personas reales. | Voz clonada sin permiso o demasiado parecida a alguien real. |
Escenarios donde multi-voz marca una diferencia real
Pregunta y respuesta
Si entrevistador e invitado suenan igual, la conversación pierde estructura.
Varios invitados
El oyente necesita distinguir roles sin mirar la pantalla todo el tiempo.
Diálogos educativos
Ejemplos con alumno, profesor o cliente se entienden mejor con voces separadas.
Cliente y soporte
Una demo de producto gana claridad cuando cada rol tiene voz propia.
Narrador y testimonios
Separar narración de declaraciones evita una sensación artificial.
Versiones por idioma
Más idiomas multiplican la necesidad de consistencia y revisión.
Audio-Mix: no basta con generar voces
Una voz generada puede sonar bien sola y aun así fallar dentro del vídeo. En multi-voz hay que escuchar el conjunto: volumen, pausas, ruido original, música, SFX, subtítulos y cambios de hablante.
Si una voz queda demasiado alta, domina la escena. Si queda baja, se pierde. Si la música tapa palabras, el doblaje parece amateur. Y si los cambios entre voces son bruscos, el vídeo se siente pegado con cinta adhesiva digital.
La mezcla no es decoración. Es el punto donde una demo se convierte en export publicable.
Cloud vs local en multi-voice dubbing
Cloud puede ser cómodo para una prueba rápida. Subes un clip, obtienes una demo y decides si el concepto funciona. Para vídeos simples o uso ocasional, esa comodidad puede ganar.
Local se vuelve interesante cuando el proyecto se repite: muchos vídeos, varios idiomas, voces autorizadas, archivos sensibles, subtítulos y exportaciones. En ese caso no solo importa la voz. Importa el sistema completo.
La decisión honesta no es “cloud malo, local bueno”. Es: cloud para velocidad inicial, local-first para control, repetición y producción más conectada.
Checklist de calidad antes del export final
- ¿Cada hablante está asignado correctamente?
- ¿Las voces se diferencian sin sonar ridículas?
- ¿La traducción suena natural en el idioma destino?
- ¿Las frases caben en el timing del vídeo?
- ¿Los subtítulos coinciden con audio y hablante?
- ¿El volumen de cada voz está equilibrado?
- ¿Hay permiso para las voces usadas?
- ¿El vídeo completo se entiende en móvil?
- ¿El export final fue revisado entero y no solo por partes?
Esta lista parece básica, pero evita el clásico desastre: una demo que suena bien y un vídeo final que se cae a pedazos.
Cómo hacer una prueba pequeña sin perder horas
La primera prueba multi-voz no debería ser un vídeo largo. Elige un clip con dos hablantes, entre 60 y 120 segundos, con audio claro y al menos un cambio de turno visible.
Ese clip debe mostrar si el flujo funciona: transcripción, speaker mapping, traducción, voces, subtítulos, mezcla y exportación. Si falla en pequeño, fallará peor en grande. Es mejor descubrirlo después de dos minutos que después de una tarde entera.
Cuando el clip corto funciona, recién entonces prueba más duración, más hablantes o más idiomas. Sí, es menos espectacular. También es mucho menos tonto.
FAQ: doblaje multi-voz local
¿Multi-Voice-Dubbing es automático?
No totalmente. La automatización puede ayudar, pero speaker mapping, voces, timing y export necesitan revisión.
¿Cuándo necesito varias voces?
Cuando el vídeo depende de diálogo, entrevistas, roles o varios hablantes reconocibles.
¿Puedo clonar voces de otras personas?
No sin permiso claro. Usa voces propias, autorizadas o voces diseñadas que no imiten personas reales.
¿Qué hardware necesito?
Para producción cómoda ayudan GPU RTX, VRAM suficiente, 32–64 GB RAM y SSD NVMe.
¿Cloud basta para pruebas?
Sí, para demos simples puede bastar. Local gana interés con control, repetición y archivos sensibles.
¿Dónde encaja VANIV?
En workflows locales que conectan vídeo, traducción, voces, subtítulos, mezcla y exportación.
Prueba un workflow local multi-voz con VANIV
Empieza con un clip corto, dos hablantes y una revisión real. Si el flujo funciona en pequeño, recién entonces escala a vídeos largos y varios idiomas.