YouTube-Interview
Ein Host spricht mit einem Gast über ein Tech-Thema. Im lokalen Workflow werden Sprecherrollen erkannt, Cues geprüft und beide Rollen mit passenden Stimmen gedubbt. Der Zuschauer versteht weiterhin, wer spricht.
Ein einzelnes Voiceover ist einfach. Wirklich spannend wird es, wenn ein Video zwei, drei oder mehr Sprecher hat. Dann brauchst du keinen TTS-Spielzeugbutton, sondern einen sauberen Workflow für Sprecher, Dialog-Cues, Stimmen, Timing, Untertitel und Export.
Dieser Guide zeigt, warum normales Video-Dubbing oft billig klingt, wie Multi-Voice-Dubbing lokal funktioniert und warum VANIV Studio für Creator interessant ist, die Videos übersetzen wollen, ohne jedes Projekt komplett in ein Cloud-System zu schieben.

Normales Dubbing reicht oft nur für Videos mit einem Sprecher. Sobald mehrere Personen sprechen, brauchst du Sprechertrennung, Dialog-Cues, Timing, passende Stimmen und einen sauberen Mix. Sonst spricht am Ende jede Person mit derselben Stimme oder die Sätze liegen schlecht auf dem Bild.
Ein lokaler Workflow ist vor allem dann spannend, wenn du regelmäßig Inhalte übersetzt, mit längeren Videos arbeitest oder sensiblen Content nicht ständig in fremde Cloud-Tools hochladen willst. Lokal heißt nicht automatisch einfacher. Aber lokal gibt dir mehr Kontrolle über Tests, Dateien, Stimmen und Export.
Viele KI-Dubbing-Demos wirken gut, solange nur eine Person spricht. Sobald ein Interview, Podcast, Panel oder Kursdialog übersetzt werden soll, beginnt die eigentliche Qualitätsprüfung.
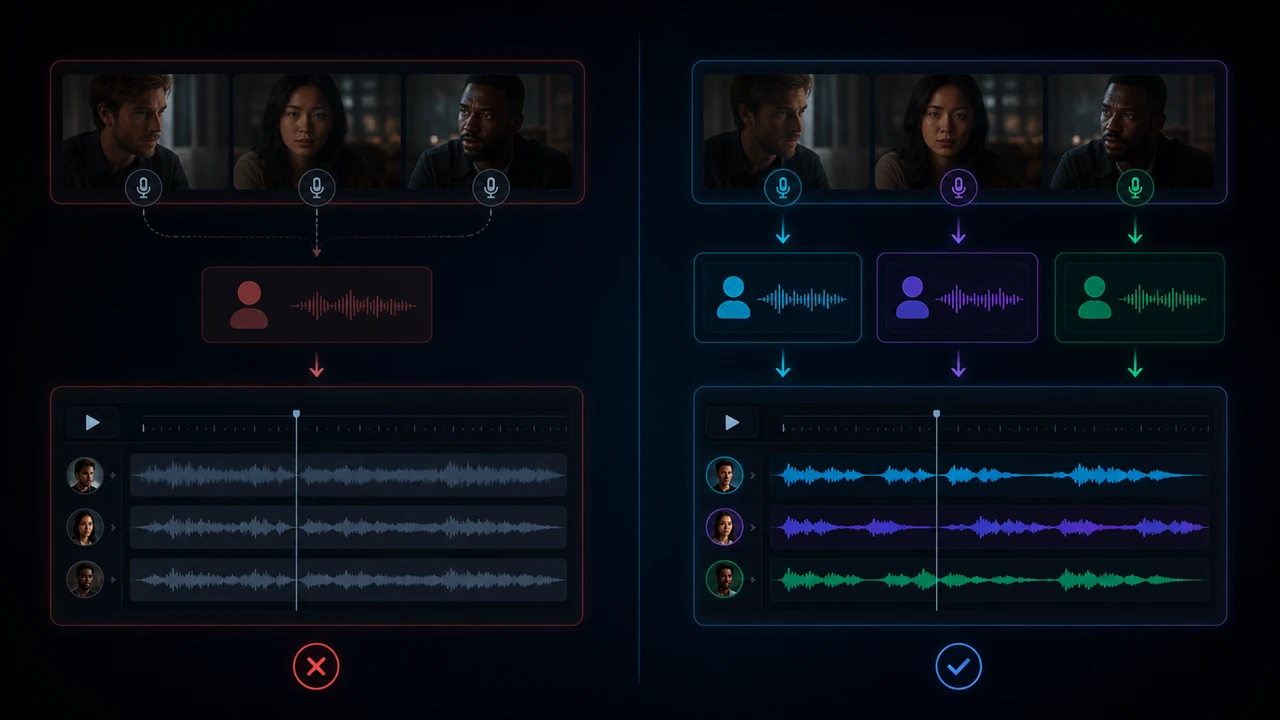
Ein einzelnes Voiceover ist relativ einfach: Text rein, Stimme wählen, Audio exportieren. Bei mehreren Sprechern reicht dieser Ansatz nicht mehr. Der Zuschauer erwartet unbewusst, dass Host, Gast, Trainer, Teilnehmer oder Erzähler unterscheidbar bleiben. Wenn plötzlich alle Personen gleich klingen, bricht die Immersion sofort.
Das ist der häufigste Fehler. Ein Interview mit zwei Personen klingt dann wie ein Monolog. Der Inhalt bleibt zwar verständlich, aber die Glaubwürdigkeit leidet.
Übersetzte Sätze sind oft länger oder kürzer als das Original. Ohne Cue-Kontrolle überlappen Sprecherwechsel, Pausen wirken falsch und der Rhythmus des Videos geht verloren.
Transkription in Tool A, Übersetzung in Tool B, Voice in Tool C und Mix in Tool D erzeugen Reibung. Jeder Export ist eine neue Fehlerquelle.
Bei echten Kundenprojekten, unveröffentlichtem Content oder persönlichen Stimmen ist jeder Upload eine bewusste Entscheidung. Ein lokaler Workflow reduziert diese Abhängigkeit deutlich.
Genau deshalb ist Multi-Voice-Dubbing kein kleines Extra, sondern ein eigener Workflow. Es geht nicht nur darum, mehrere Audiodateien zu erzeugen. Es geht um Sprechererkennung, Dialog-Cues, Stimmenzuordnung, Übersetzungslänge, Timing, Untertitel, Mix und finalen Export.
Gutes Multi-Voice-Dubbing entsteht nicht durch einen magischen Button. Es entsteht durch eine Kette aus sauberen Entscheidungen.
VANIV ist local-first gedacht: Die Verarbeitung läuft lokal auf deinem Windows-PC. Dadurch reduzierst du Cloud-Abhängigkeit, Uploads und Credit-Druck. Rechte, Einwilligungen und saubere Stimmenzuordnung bleiben trotzdem deine Verantwortung.
Nicht jedes Video braucht mehrere Stimmen. Aber sobald Dialog, Interview oder Rollenwechsel wichtig sind, wird Single-Voice schnell zu dünn.
Wenn der Zuschauer im Original klar erkennt, dass unterschiedliche Personen sprechen, sollte die übersetzte Version das ebenfalls abbilden. Sonst wirkt das Ergebnis schnell wie billige Automation.
Multi-Voice-Dubbing ist besonders stark, wenn ein Video nicht nur übersetzt, sondern als neue Sprachversion ernst genommen werden soll.
Ein Host spricht mit einem Gast über ein Tech-Thema. Im lokalen Workflow werden Sprecherrollen erkannt, Cues geprüft und beide Rollen mit passenden Stimmen gedubbt. Der Zuschauer versteht weiterhin, wer spricht.
Bei längeren Gesprächen ist Konsistenz entscheidend. Wenn Host und Co-Host über 20 Minuten gleich bleiben, fühlt sich die Sprachversion deutlich professioneller an.
Trainer, Teilnehmerfrage und Erklärung sollten nicht gleich klingen. Multi-Voice hilft, Lerninhalte übersichtlich und natürlicher zu halten.
Storytelling-Videos profitieren von Rollen: Erzähler, Kommentar, Charakter oder Gegenstimme. Voice Design kann hier mehrere wiederverwendbare Rollen erzeugen.
Ein Produktvideo kann zwischen Erzähler, Nutzerfrage und Support-Antwort wechseln. So entsteht mehr Dynamik als bei einem einzigen langen Voiceover.
Wenn ein Video in mehrere Sprachen übertragen wird, sollte die Sprecherlogik erhalten bleiben. Sonst skaliert zwar der Output, aber nicht die Qualität.
Wichtig ist: Multi-Voice-Dubbing ersetzt keine redaktionelle Kontrolle. Du solltest mindestens Stichproben prüfen: Sprecherwechsel, Übersetzungslänge, Fachbegriffe, Pausen, Untertitel und finalen Mix.
Multi-Voice-Dubbing ist kein Effekt für Show-Demos. Es wird dann wertvoll, wenn du echte Inhalte mit mehreren Stimmen international nutzbar machen willst.
Besonders spannend ist lokales Multi-Voice-Dubbing für Creator, die bestehende Videos in mehrere Sprachen bringen möchten, ohne jedes Mal Sprecher, Studio und mehrere Cloud-Tools zu koordinieren. Ein Interview, ein Podcast, ein Online-Kurs oder ein YouTube-Video mit mehreren Personen braucht mehr als nur eine übersetzte Tonspur. Es braucht eine klare Sprecherlogik.
Wenn du ein Video mit mehreren Sprechern übersetzen willst, entscheidet die Zuordnung der Stimmen über den professionellen Eindruck. Der Host sollte wie der Host wirken. Der Gast sollte klar unterscheidbar bleiben. Ein Erzähler sollte nicht plötzlich wie ein Interviewpartner klingen. Genau hier wird Speaker Mapping wichtig: Jeder Sprecher bekommt eine eigene Rolle, eine passende Stimme und eigene Dialog-Cues.
Wenn ein Kanal international wachsen soll, reicht eine rohe Untertitelspur oft nicht mehr. Multi-Voice-Dubbing hilft, Videos in Deutsch, Englisch oder andere Sprachen zu bringen, ohne die Sprecherstruktur zu verlieren.
Podcasts und Interviews leben von den Personen. Ein lokaler Multi-Voice-Workflow hält Host, Gast und Zwischenfragen besser getrennt als ein einziges KI-Voiceover.
Kurse enthalten oft Trainerstimme, Teilnehmerfragen, Beispiele und Erklärpassagen. Mehrere Stimmen machen die übersetzte Version leichter verständlich und weniger monoton.
Storytelling, Erklärvideos und dokumentarische Formate können mit verschiedenen Rollen deutlich hochwertiger wirken: Erzähler, Kommentar, Gegenposition oder Charakterstimme.
Der große Vorteil eines lokalen Workflows: Du kannst Varianten testen, Stimmen wiederverwenden und Fehler korrigieren, ohne jedes Zwischenmaterial erneut in verschiedene Cloud-Dienste zu schieben. Gerade bei wiederkehrender Produktion entsteht daraus ein echter Produktionsvorteil. Ein guter lokaler Dubbing-Workflow spart nicht nur Kosten, sondern reduziert Reibung: weniger Exporte, weniger Tool-Wechsel, weniger verlorene Projektstände.
Wer nach „Multi-Voice-Dubbing lokal“, „Video mit mehreren Sprechern übersetzen“, „Podcast übersetzen mit KI“ oder „YouTube-Video mehrsprachig machen“ sucht, will meistens keine Spielerei. Diese Nutzer suchen einen Workflow, der Sprecherrollen, Stimmen, Timing, Untertitel und Export zusammenbringt. Genau dort positioniert sich VANIV Studio.
Eine gute Stimmenzuordnung ist nicht nur technisch. Sie entscheidet auch darüber, ob dein Video fair, verständlich und rechtlich sauber bleibt.
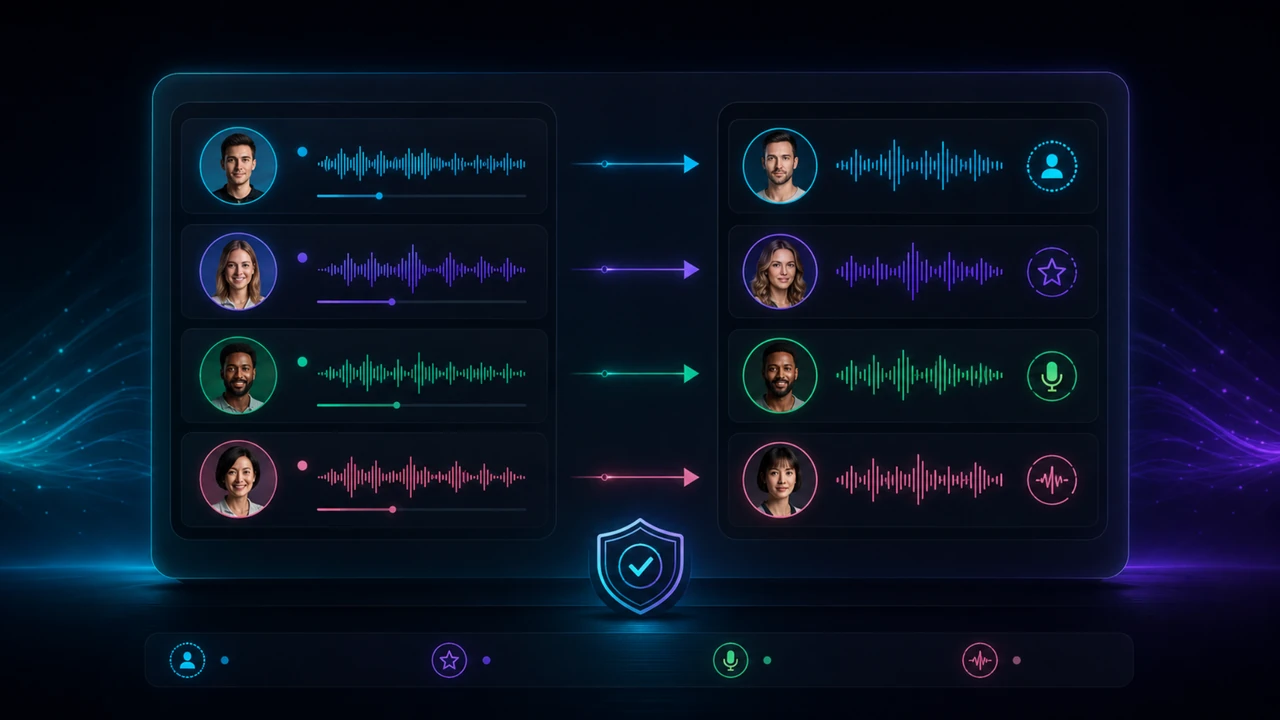
Im Multi-Voice-Dubbing brauchst du eine klare Zuordnung: Sprecher A bekommt Stimme A, Sprecher B bekommt Stimme B, Erzähler bekommt Stimme C. Diese Logik sollte sichtbar und korrigierbar sein. Gerade bei Interviews oder Kundenprojekten darf eine falsche Stimme nicht einfach unbemerkt durchlaufen.
Wenn du eine klare Erlaubnis hast, kann eine geklonte Stimme sinnvoll sein. Das ist besonders spannend für eigene Kanäle, autorisierte Sprecher oder persönliche Marken.
Wiederverwendbare Stimmen sind ideal für wiederkehrende Formate. Ein Host, eine Kursstimme oder eine Markenstimme kann so über viele Videos konsistent bleiben.
Wenn keine echte Stimme geklont werden soll, ist Voice Design oft sauberer. Du beschreibst eine neue Rolle statt eine reale Person nachzubauen.
Automatische Sprechererkennung ist hilfreich, aber nicht heilig. Overlaps, Lachen, Zwischenrufe und kurze Einwürfe brauchen manchmal manuelle Korrektur.
VANIV soll nicht nur eine Stimme erzeugen, sondern den kompletten lokalen Produktionsfluss sichtbar machen.
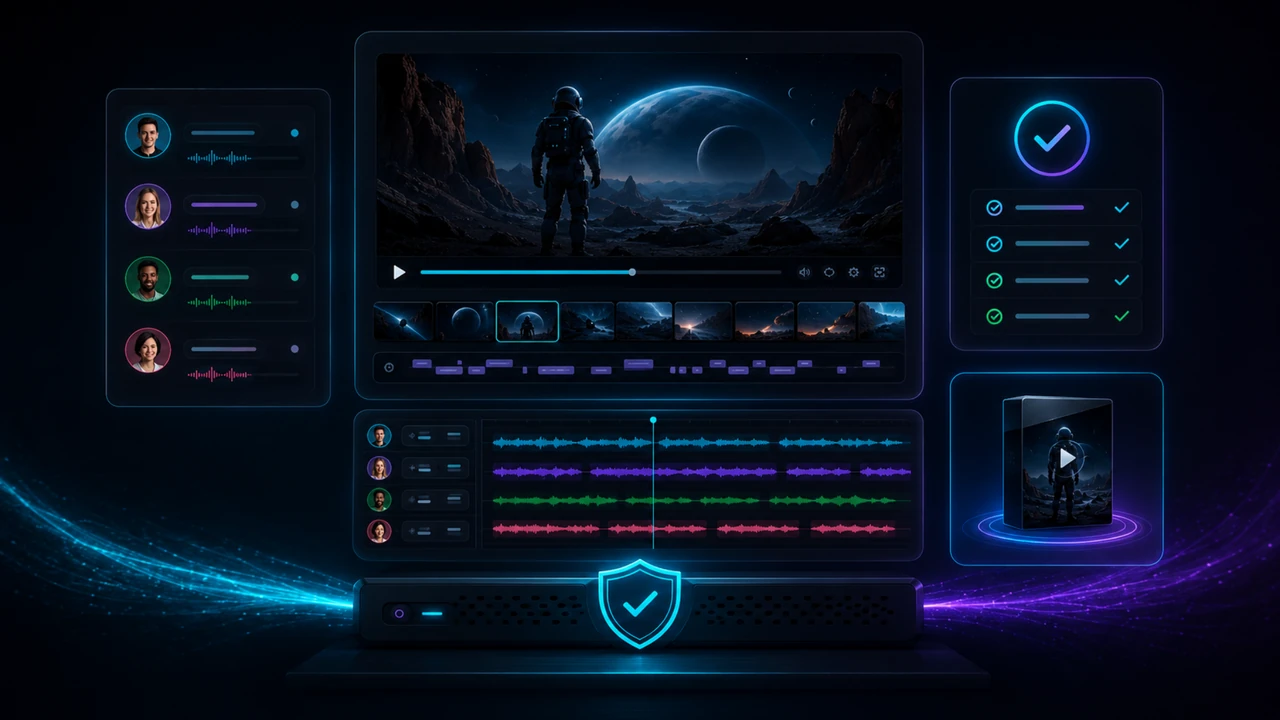
Der VANIV-Ansatz ist ein zusammenhängender Workflow: Video importieren, Audio analysieren, Sprecherrollen erkennen, Dialog-Cues erstellen, Übersetzung prüfen, Stimmen zuweisen, Dubbing erzeugen, Untertitel kontrollieren und den finalen Export vorbereiten. Dadurch entsteht weniger Tool-Hopping und weniger Datei-Chaos.
Du arbeitest nicht nur mit einem großen Textblock, sondern mit prüfbaren Segmenten. Das hilft bei Sprecherwechseln, Pausen, Timing und manueller Korrektur.
Je nach Projekt kannst du mit eigener Stimme, gespeicherten Stimmen, Standardstimmen oder Voice Design arbeiten. Entscheidend ist, dass jede Rolle nachvollziehbar bleibt.
Untertitel sind nicht nur Zusatzfunktion. Sie zeigen dir, ob Übersetzung, Timing und Satzlänge im Video funktionieren.
Eine Dubbing-Spur muss mit Hintergrund, Musik, Pausen und Export zusammenpassen. Erst dann wirkt das Ergebnis wie eine echte Produktion.
Creator brauchen wiederholbare Abläufe. Ein einzelner Wow-Export bringt wenig, wenn du beim nächsten Video wieder bei null beginnst. Multi-Voice-Dubbing wird erst stark, wenn Sprecherrollen, Stimmen, Timing und Export als System funktionieren.
Für kurze Tests brauchst du nicht automatisch den teuersten PC. Für regelmäßige Produktion zählt aber Reserve.
Multi-Voice-Dubbing belastet dein System stärker als einfaches Text-to-Speech. Du hast Video, Audioanalyse, Sprecherlogik, Übersetzung, mehrere Stimmen, Untertitel und Export im gleichen Projekt. Je länger das Video und je mehr Sprecher beteiligt sind, desto wichtiger werden GPU, VRAM, RAM und schnelle SSD.
Für kleine Clips, einzelne Sprecherwechsel und erste Experimente reicht oft ein solides Setup. Entscheidend ist, dass du realistische Testclips verwendest.
Wenn du jede Woche Videos übersetzt, brauchst du mehr Reserve. Sonst wird jeder Testlauf zur Geduldsprobe.
Für lokale KI-Audio- und Video-Workflows ist eine moderne NVIDIA RTX-GPU in der Praxis deutlich angenehmer. Mehr Details findest du im GPU-Guide.
Hardware allein rettet keinen schlechten Prozess. Kurze Cues, saubere Testläufe und kontrollierte Exporte sparen oft mehr Zeit als blinde Maximalleistung.
Gute Ergebnisse beginnen vor dem ersten Render. Wer schlechtes Ausgangsmaterial nutzt, bekommt später mehr Korrekturarbeit.
Auch ein lokaler Workflow macht schlechtes Ausgangsmaterial nicht magisch perfekt. Sehr laute Hintergrundmusik, starke Überschneidungen, Hall, schlechte Mikrofone oder chaotische Gesprächssituationen können weiterhin manuelle Korrektur brauchen.
Auch Lip-Sync ist ein eigenes Thema. Multi-Voice-Dubbing kann Sprecherrollen, Stimmen, Übersetzung und Timing verbessern. Perfekte Mundbewegungen in jeder Szene sind aber ein separater Arbeitsschritt und sollten nicht als automatisch garantiert verkauft werden.
Der ehrliche Vorteil von VANIV liegt nicht in unrealistischen Versprechen, sondern in Kontrolle: Du siehst den Workflow, kannst prüfen, korrigieren, wiederholen und lokal arbeiten.
Ein Dubbing klingt erst dann professionell, wenn Stimme, Timing, Untertitel, Hintergrund und Lautstärke zusammenpassen.
Stimmen müssen an den richtigen Stellen wechseln. Besonders kurze Einwürfe und Overlaps verdienen Aufmerksamkeit.
Gute Pausen wirken natürlich. Zu enge Cues klingen hektisch, zu lange Pausen wirken leer.
Untertitel zeigen schnell, ob die Übersetzung zu lang ist oder nicht zum Video passt.
Sprache muss klar sein, aber Hintergrund und Musik dürfen nicht komplett sterben. Der Mix entscheidet über den professionellen Eindruck.
Viele schlechte Dubs scheitern nicht am Modell, sondern an einem unkontrollierten Workflow.
Wenn du Multi-Voice-Dubbing ernsthaft nutzen willst, sind diese Themen die logischen nächsten Schritte.
Der komplette lokale Workflow für Übersetzung, Dubbing, Untertitel und Export.
Video-Workflow ansehen →So bereitest du eigene oder autorisierte Stimmen für lokale Workflows vor.
Voice Cloning Guide lesen →Wenn du keine echte Stimme klonen willst, ist Voice Design oft der sauberere Weg.
Voice Design verstehen →Vergleiche Cloud-Voice-Tools mit einem lokalen VANIV Workflow.
Alternative vergleichen →Welche Hardware lokale Voice-, TTS- und Dubbing-Workflows angenehmer macht.
GPU-Guide lesen →Warum Stimmen, Einwilligung und Kennzeichnung bei KI-Audio wichtig bleiben.
Rechte sauber klären →VANIV Studio ist im Early Access. Frage eine unverbindliche Testlizenz an und prüfe mit deinem eigenen Material, ob dein PC und dein Workflow passen.