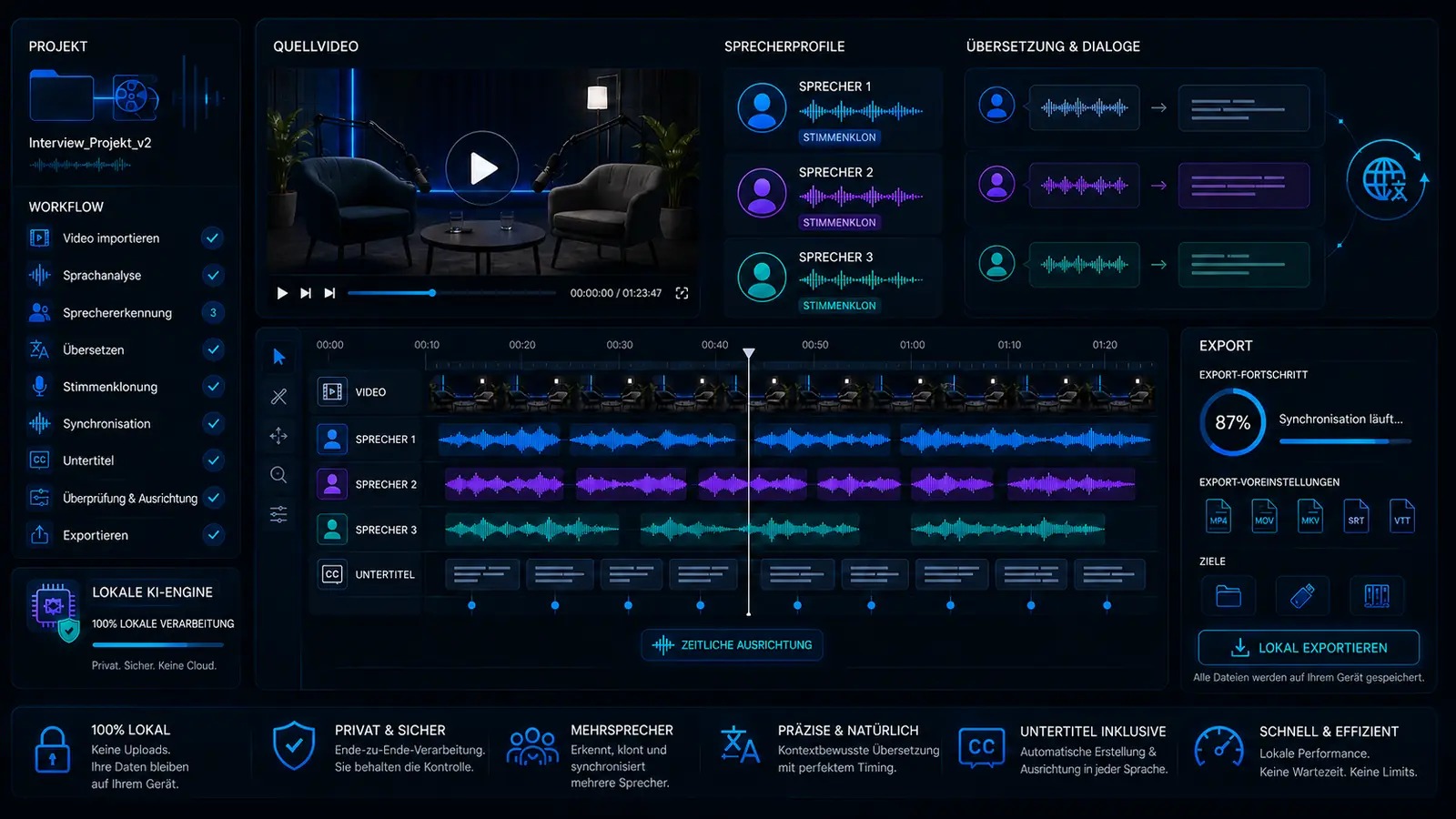
Multi-Speaker-Dubbing mit KI: Videos mit mehreren Sprechern übersetzen und vertonen
Multi-Speaker-Dubbing ist deutlich anspruchsvoller als ein normales Voiceover. Sobald mehrere Personen sprechen, müssen Sprecherrollen, Timing, Dialogstruktur, Stimmen, Untertitel und Export sauber zusammenpassen. VANIV denkt diesen Prozess als lokalen KI-Dubbing-Workflow für Interviews, Podcasts, Dialogvideos, Kurse und Creator-Projekte.
Was ist Multi-Speaker-Dubbing?
Multi-Speaker-Dubbing beschreibt Dubbing-Workflows, bei denen mehr als eine Stimme im Video vorkommt.
Mehrere Sprecher sauber verständlich halten
Bei einem normalen Voiceover gibt es oft nur eine Hauptstimme. Bei Interviews, Podcasts, Dialogvideos, Kursen oder Szenen mit mehreren Personen ist das anders. Der Workflow muss erkennen, wer spricht, wann gesprochen wird und welche Stimme im Zielvideo welche Rolle übernimmt.
Dubbing als strukturierter Dialog-Workflow
VANIV sollte Multi-Speaker-Dubbing nicht als bloßes Extra verkaufen. Es ist ein eigener Workflow innerhalb von Video-Dubbing, Video-Übersetzung und Voice Cloning. Entscheidend ist, dass Dialoge verständlich und Sprecherrollen nachvollziehbar bleiben.
Wenn Sprecherrollen durcheinander geraten, wirkt selbst eine gute Übersetzung schwach. Multi-Speaker-Dubbing braucht deshalb mehr Kontrolle als ein simples „Text rein, Stimme raus“-Tool.
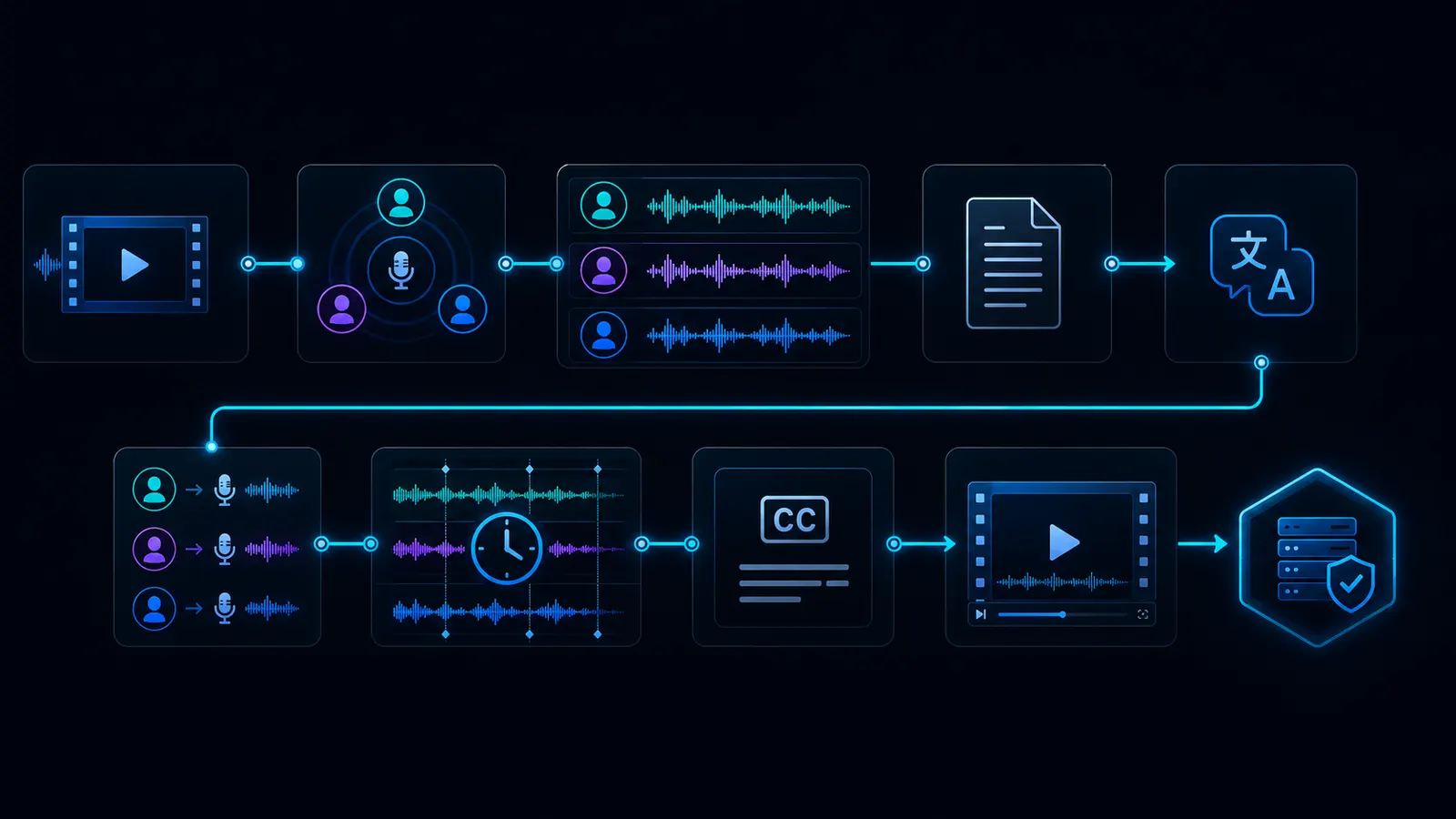
Wie ein lokaler Multi-Speaker-Dubbing-Workflow aussehen kann
Der genaue Ablauf hängt vom Material ab. Die Grundlogik bleibt: Sprecher erkennen, Text verstehen, übersetzen, Stimmen zuordnen, Timing prüfen und exportieren.
Import
Das Originalvideo oder die Audiodatei wird in den Workflow geladen.
Sprecher erkennen
Der Workflow versucht, verschiedene Sprecherrollen oder Segmente zu unterscheiden.
Transkript
Die gesprochenen Inhalte werden in Text umgewandelt und einzelnen Abschnitten zugeordnet.
Übersetzung
Der Dialog wird in die Zielsprache übertragen, ohne Sinn und Rollen zu verlieren.
Stimmen
Die passende Zielstimme wird pro Sprecherrolle gewählt oder vorbereitet.
Timing
Sätze, Pausen, Wechsel und Unterbrechungen müssen zum Video passen.
Review
Namen, Fachbegriffe, Rollen, Reihenfolge und Tonalität werden geprüft.
Export
Die neue Sprachversion wird mit Audio, Untertiteln und Projektstruktur exportiert.
Warum mehrere Sprecher beim KI-Dubbing so anspruchsvoll sind
Ein einzelner Sprecher ist relativ leicht kontrollierbar. Mehrere Sprecher bringen sofort neue Fehlerquellen.
Der Zuschauer muss wissen, wer spricht
Wenn ein Interview in eine andere Sprache übertragen wird, müssen Sprecherrollen erhalten bleiben. Sobald Stimmen falsch zugeordnet werden, verliert der Zuschauer Orientierung. Das ist besonders kritisch bei Interviews, Podcasts, Panel-Videos und Dialogszenen.
Menschen sprechen nicht sauber nacheinander
In echten Gesprächen gibt es Unterbrechungen, Lachen, kurze Einwürfe und Überschneidungen. Genau diese kleinen Stellen machen Multi-Speaker-Dubbing kompliziert. Ein guter Workflow muss damit besser umgehen als ein simples Einzelsprecher-Voiceover.
Jede Rolle braucht eine passende Stimme
Bei mehreren Personen reicht eine einzige KI-Stimme nicht aus. Je nach Projekt braucht jede Rolle eine eigene Stimme, eine passende Tonalität oder eine klare Sprecherunterscheidung. Sonst klingt das Ergebnis flach oder verwirrend.
Dialoge leben von Rhythmus
Dialoge funktionieren nicht nur über Text. Pausen, Tempo und Wechsel erzeugen Verständlichkeit. Wenn die neue Sprache zu lang, zu kurz oder falsch platziert ist, wirkt der Dialog künstlich.
Für welche Inhalte Multi-Speaker-Dubbing besonders sinnvoll ist
Gespräche international nutzbar machen
Interviews enthalten oft wertvolle Aussagen, Expertenwissen oder persönliche Geschichten. Multi-Speaker-Dubbing kann helfen, diese Inhalte für neue Zielgruppen zugänglich zu machen, ohne das Format komplett neu aufzunehmen.
Audio- und Video-Podcasts übersetzen
Podcasts mit zwei oder mehr Stimmen sind typische Kandidaten. Besonders Evergreen-Folgen, Experteninterviews oder Business-Podcasts können in mehreren Sprachen länger verwertbar werden.
Trainings mit mehreren Rollen verständlich halten
In Schulungen, Kursen oder Tutorials gibt es manchmal Trainer, Gäste, Moderator und Teilnehmer. Wenn diese Rollen erhalten bleiben, wirkt die Sprachversion deutlich natürlicher.
Kundeninhalte professioneller lokalisieren
Agenturen können Multi-Speaker-Dubbing für Kundeninterviews, Produktvideos, Testimonials oder Webinar-Ausschnitte nutzen. Dabei zählt nicht nur Geschwindigkeit, sondern auch saubere Rechte-, Stimmen- und Projektstruktur.
Was gutes Multi-Speaker-Dubbing ausmacht
Die Qualität hängt nicht nur von der Übersetzung ab. Entscheidend sind Sprechertrennung, Stimmenlogik, Timing und Review.
Gute Ausgangsqualität spart Probleme
Je klarer die einzelnen Stimmen im Original hörbar sind, desto besser kann der Workflow Sprecherwechsel, Transkript und Timing verarbeiten. Starker Hall, laute Musik und überlappende Stimmen machen das Ergebnis schwieriger.
Jede Stimme braucht eine klare Funktion
Bei Dialogen ist es wichtig, dass Stimmen unterscheidbar bleiben. Nicht jede Rolle braucht eine spektakuläre Stimme, aber jede Rolle braucht eine nachvollziehbare Zuordnung.
Dialogsprache muss natürlich bleiben
Gesprochener Dialog funktioniert anders als geschriebener Text. Eine gute Übersetzung muss kurz genug, verständlich und natürlich sein. Sonst klingt die gedubbte Version wie vorgelesene Untertitel.
Sprecherfehler fallen sofort auf
Wenn Rollen vertauscht werden oder ein Satz zur falschen Stimme gehört, fällt das schnell auf. Deshalb ist Review bei Multi-Speaker-Dubbing noch wichtiger als bei einem Einzelsprecher-Voiceover.
Stimmen, Zustimmung und Verantwortung bei mehreren Sprechern
Mehrere Sprecher bedeuten auch mehrere Rechtefragen. Das muss sauber behandelt werden.
Jede Stimme gehört zu einer Person
Wenn echte Stimmen geklont oder imitiert werden, braucht es klare Zustimmung. Bei Interviews, Podcasts und Kundenvideos ist das besonders wichtig, weil mehrere Personen betroffen sein können.
Bei Kundenprojekten lieber sauber kommunizieren
Für Agenturen und professionelle Creator ist Vertrauen wichtiger als ein schneller Trick. Je nach Kontext sollte klar sein, dass KI-Dubbing oder synthetische Stimmen verwendet werden.
Lokal-first hilft bei sensiblen Projekten
Lokale Workflows können helfen, Rohmaterial, Stimmen und Projektdateien kontrollierter zu verwalten. Das ersetzt keine Rechteprüfung, reduziert aber unnötige Plattformwechsel.
Professionell statt gruselig
VANIV sollte Multi-Speaker-Dubbing als seriösen Produktionsworkflow positionieren: eigene oder autorisierte Stimmen, klare Projektstruktur, Review und Export. Nicht als Spielzeug für Täuschung.
Welche Multi-Speaker-Videos solltest du zuerst dubben?
Nicht jedes Gespräch muss sofort in mehrere Sprachen. Starte mit Inhalten, die langfristig Wert haben.
Interviews mit dauerhaftem Thema zuerst
Ein aktueller News-Talk kann schnell veralten. Ein gutes Experteninterview, ein Tutorial-Gespräch oder ein Produkt-Webinar kann dagegen lange relevant bleiben. Solche Inhalte eignen sich besser für Dubbing.
Inhalte mit bestehender Nachfrage wählen
Wenn ein Video bereits Watchtime, Kommentare, Leads oder Suchinteresse zeigt, ist es ein besserer Kandidat als ein zufälliger Clip. Dubbing sollte dort starten, wo Nachfrage sichtbar ist.
Mit überschaubaren Gesprächen starten
Ein Interview mit zwei klar getrennten Stimmen ist einfacher als ein chaotisches Gruppengespräch. Für den Einstieg sind kurze, klare Projekte besser, weil Review und Qualitätskontrolle leichter bleiben.
Erst beweisen, dann skalieren
Die beste Strategie ist nüchtern: ein starkes Video auswählen, eine Sprachversion testen, Reaktion prüfen und erst danach den Workflow ausbauen. So wird Multi-Speaker-Dubbing zu einem Produktionshebel statt zu einer technischen Spielerei.
Typische Fehler bei Multi-Speaker-Dubbing
Mehrere Sprecher machen Dubbing schnell komplex. Viele Ergebnisse scheitern nicht an der Übersetzung, sondern an Strukturproblemen.
Wenn Sprecher vertauscht werden
Der häufigste Fehler ist eine falsche Sprecherzuordnung. Wenn Person A plötzlich mit der Stimme von Person B spricht, verliert der Zuschauer sofort Orientierung. Bei Interviews, Podcasts und Dialogvideos wirkt das besonders störend, weil die Beziehung zwischen den Personen Teil des Inhalts ist.
Wenn niemand mehr unterscheidbar ist
Auch wenn die Zuordnung technisch stimmt, können zu ähnliche Stimmen problematisch sein. Bei mehreren Sprecherrollen sollte der Zuschauer hören können, wer gerade spricht. Das bedeutet nicht, dass jede Stimme extrem anders klingen muss, aber sie braucht eine klare Funktion im Gespräch.
Wenn Dialoge ihren Rhythmus verlieren
Dialog lebt von Pausen, Reaktionen und Wechseln. Wenn eine übersetzte Stimme zu lang wird, zu früh einsetzt oder Einwürfe verschluckt, fühlt sich das Gespräch künstlich an. Genau deshalb ist Timing bei Multi-Speaker-Dubbing wichtiger als bei einfachem Voiceover.
Blind exportieren ist gefährlich
Bei mehreren Sprechern muss fast immer geprüft werden: Wer spricht? Passt die Stimme? Stimmen Namen und Begriffe? Ist der Dialog verständlich? Ein lokaler Workflow ist wertvoll, aber ohne Review bleibt das Ergebnis schnell halbgar.
Wie du Stimmen bei mehreren Sprechern sinnvoll zuordnest
Nicht jedes Projekt braucht perfekte Stimmklone. Entscheidend ist, dass Rollen verständlich, rechtlich sauber und wiederholbar bleiben.
Wenn echte Personen wiedererkennbar bleiben sollen
Wenn ein Creator, Moderator oder Experte mit eigener Stimme erkennbar bleiben soll, kann Voice Cloning sinnvoll sein. Dann braucht es aber klare Zustimmung und eine saubere Referenzaufnahme. Ohne diese Grundlage wird der Workflow schnell riskant.
Wenn nur die Sprecherrolle wichtig ist
Nicht jede Rolle muss exakt wie das Original klingen. Bei Kursen, Erklärvideos oder internen Trainings kann es reichen, unterschiedliche synthetische Stimmen zu nutzen, solange die Rollen eindeutig bleiben. Das kann einfacher, schneller und rechtlich klarer sein.
Die gleiche Rolle sollte gleich bleiben
Wenn du mehrere Episoden, Kursmodule oder Interviewausschnitte bearbeitest, sollte dieselbe Rolle nicht ständig anders klingen. Konsistente Stimmen helfen Zuschauern, sich zu orientieren. Das ist besonders wichtig für Serienformate und wiederkehrende Sprecher.
Stimmenlogik gehört in den Workflow
Der Vorteil von VANIV liegt nicht darin, einfach mehrere Audiospuren zu erzeugen. Der Vorteil liegt darin, Sprecherrollen, Stimmen, Übersetzung, Untertitel und Export als zusammenhängenden lokalen Workflow zu denken. Genau das unterscheidet ein Studio von einem Einzelgenerator.
Review-Checkliste vor dem Export
Bevor ein Multi-Speaker-Dub veröffentlicht wird, sollte er nüchtern geprüft werden. Sonst ruinieren kleine Fehler den professionellen Eindruck.
Sind alle Rollen korrekt zugeordnet?
Prüfe, ob jeder Satz zur richtigen Person gehört. Das klingt banal, ist aber bei Interviews und Podcasts der wichtigste Qualitätscheck. Ein einziger Rollenfehler kann die Glaubwürdigkeit der ganzen Sprachversion beschädigen.
Funktioniert der Dialog ohne Original?
Höre die neue Sprachversion so, als würdest du das Original nicht kennen. Sind Fragen und Antworten logisch? Sind Einwürfe verständlich? Klingt das Gespräch natürlich oder wie ein zerhacktes Skript?
Passen Untertitel und Stimmen zusammen?
Wenn Untertitel verwendet werden, müssen sie zur gesprochenen Version passen. Sie müssen nicht jedes Wort identisch wiedergeben, aber Reihenfolge, Sinn und Begriffe sollten übereinstimmen.
Ist die Datei bereit für YouTube, Kunden oder Website?
Prüfe Lautstärke, Format, Sprache, Dateiname, Untertitel und Zielplattform. Ein Webinar-Clip für Kunden braucht andere Sorgfalt als ein schneller Social-Test. Je professioneller der Einsatz, desto wichtiger ist der letzte Check.
Beispiel: Ein Interview mit zwei Sprechern in eine neue Sprache bringen
Ein konkreter Ablauf macht besser verständlich, warum Multi-Speaker-Dubbing mehr ist als eine normale Übersetzung.
Ein Moderator interviewt einen Experten
Stell dir ein 15-Minuten-Interview vor: ein Moderator stellt Fragen, ein Experte antwortet, zwischendurch gibt es kurze Reaktionen, Pausen und Nachfragen. Für Zuschauer ist sofort klar, wer welche Rolle hat. Genau diese Rollenlogik muss auch in der gedubbten Sprachversion erhalten bleiben.
Fragen und Antworten dürfen nicht vermischt werden
Bei der Übersetzung zählt nicht nur der Inhalt einzelner Sätze. Der Gesprächsfluss muss verständlich bleiben. Eine Frage muss wie eine Frage klingen, eine Antwort muss zur richtigen Person gehören, und kurze Einwürfe dürfen nicht wie Hauptaussagen wirken.
Jede Rolle braucht eine passende Klanglogik
Der Moderator kann eine klare, neutrale Stimme bekommen, während der Experte ruhiger oder fachlicher klingt. Wenn echte Stimmen wiedererkennbar bleiben sollen, braucht es Zustimmung. Wenn nur die Rollen verständlich bleiben müssen, können auch passende synthetische Stimmen reichen.
Am Ende zählt Verständlichkeit, nicht Technik-Show
Ein gutes Multi-Speaker-Dubbing merkt man daran, dass der Zuschauer dem Gespräch folgen kann, ohne über die Technik nachzudenken. Sprecherrollen, Untertitel, Timing und Export wirken dann wie ein sauberer Produktionsworkflow. Genau darauf sollte VANIV ausgerichtet sein.
Wann Multi-Speaker-Dubbing nicht die beste Wahl ist
Eine ehrliche Seite sollte nicht so tun, als wäre jeder Inhalt automatisch ein guter Dubbing-Kandidat.
Wenn alle gleichzeitig sprechen
Gruppengespräche mit vielen Überlappungen, Hintergrundlärm und unklaren Sprecherwechseln sind schwer zu bearbeiten. In solchen Fällen kann zuerst eine gekürzte Version, ein separates Voiceover oder eine saubere Untertitel-Fassung sinnvoller sein als sofort vollständiges Multi-Speaker-Dubbing.
Wenn der Inhalt morgen schon veraltet ist
Für sehr kurze News-Clips oder spontane Social-Videos lohnt sich der Aufwand nicht immer. Multi-Speaker-Dubbing ist stärker bei Inhalten, die länger genutzt werden: Interviews, Kurse, Produktdemos, Webinare, Podcasts und hochwertige Creator-Videos.
Wenn Stimmen und Zustimmung ungeklärt sind
Wenn nicht klar ist, ob alle beteiligten Personen mit Dubbing, synthetischen Stimmen oder Voice Cloning einverstanden sind, sollte das Projekt nicht blind umgesetzt werden. Gerade bei mehreren Sprechern ist saubere Zustimmung wichtiger als Geschwindigkeit.
Erst klare Projekte, dann komplexe Formate
Der beste Einstieg ist ein überschaubares Interview mit zwei klar getrennten Stimmen und guter Audioqualität. So kannst du Workflow, Timing, Übersetzung und Review sauber testen, bevor du größere Podcasts, Panels oder komplexe Dialogvideos angehst.

Welche VANIV-Seite solltest du danach lesen?
Multi-Speaker-Dubbing verbindet mehrere Kernbereiche. Diese Seiten erklären die wichtigsten Bausteine genauer.
Der Hauptworkflow für Sprachversionen, Stimme, Timing, Untertitel und Export.
TranslateVideo übersetzenDie Grundlage für Transkript, Übersetzung und mehrsprachige Video-Versionen.
VoiceStimme klonenFür eigene oder autorisierte Stimmen in Creator- und Dubbing-Workflows.
OfflineOffline KI Stimme generierenFür lokale Sprachgenerierung ohne reine Cloud-Abhängigkeit.
StudioLokales KI-StudioDie zentrale Seite zur lokalen VANIV-Produktlogik.
HubAlle LösungenDer Überblick über Voice, Dubbing, Übersetzung, Hardware und lokale KI.
Häufige Fragen zu Multi-Speaker-Dubbing
Was ist Multi-Speaker-Dubbing?
Multi-Speaker-Dubbing bedeutet, Videos mit mehreren Sprecherrollen in eine neue Sprache zu übertragen und dabei Stimmen, Timing und Dialogstruktur verständlich zu halten.
Ist das schwieriger als normales Dubbing?
Ja. Mehrere Sprecher bedeuten mehr Zuordnung, mehr Timing-Probleme und mehr Review-Aufwand.
Eignet sich das für Interviews?
Ja, besonders für Experteninterviews, Podcasts, Webinare, Panel-Videos und Kundengespräche mit langfristigem Wert.
Brauche ich mehrere geklonte Stimmen?
Nicht immer. Manchmal reichen unterschiedliche synthetische Stimmen. Wenn echte Personen wiedererkennbar bleiben sollen, braucht es klare Zustimmung.
Kann ich Podcasts damit übersetzen?
Ja, vor allem strukturierte Audio- oder Video-Podcasts mit klar getrennten Sprechern sind gute Kandidaten.
Warum ist lokales Multi-Speaker-Dubbing interessant?
Weil Interviews, Stimmen und Kundenvideos sensible Inhalte sein können. Ein lokaler Workflow gibt mehr Kontrolle über Material, Stimmen und Export.
Welche Hardware hilft?
Für längere Videos und mehrere Stimmen sind moderne GPU, genug VRAM, RAM und schnelle SSD sinnvoll.
Welche Seite ist als Nächstes sinnvoll?
Lies danach Video-Dubbing, Video übersetzen oder Stimme klonen.
Mehrere Sprecher brauchen mehr als nur eine neue Tonspur.
VANIV Studio verbindet Sprecherrollen, Voice Cloning, Übersetzung, Timing, Untertitel und Export zu einem lokalen Workflow für Interviews, Podcasts, Dialogvideos und Creator-Projekte.
Testlizenz anfragen